想要了解更多行业详情请加微,加了就领算力,更多福利活动等您参加。链芯云证科技——头部矿商企业、集系统开发、节点搭建、超算集群服务、IDC机房托管、运维托管于一体的高科技企业!
现在加微,即可免费赠送两个Bzz节点、前面出票,后面挖矿,T+0出节点!
Swarm是以前以太坊上的一个点对点全球化文件系统,是目前为止和IPFS对标的唯二的P2P全球化文件系统。

SWARM是个啥
技术总是繁琐的,我尽量简单点。
哈希运算
哈希运算是一系列算法的总称,反正就是对一段数据进行处理,得到一个固定大小(一般是32字节)的结果,这个结果称为哈希值 。并且原始数据不同,得到相同哈希值的概率非常非常非常小,这样的过程称为哈希运算。哈希运算其实是让一个固定长度,相对短的数据来表征一个任意长度的数据。
内容地址
任意的一段数据,对数据内容进行一次哈希运算的结果(哈希值),可以称为这个数据的内容地址。这个称谓的来源是因为地址是由内容决定的。
分布式哈希表
每个节点设备,同样有一个地址,这个地址的来源可以一段随机数的哈希值,一旦生成,节点的地址就不变。这里可以看到节点地址和内容地址是同类型的,这个称为节点与数据“同构”。
既然都是32字节的数据,我们就可以计算两个地址之间的“距离”,这个距离是“逻辑距离”和实际的物理位置无关。计算距离可以有多种算法,最常用的是异或。我们这里为了方便理解,可以理解为两个地址值相减,相减的结果越小,地址就越近。
有了内容地址和逻辑距离的概念,我们可以这样实现分布式哈希表:
任何的数据,在全网中都可以推送到离其内容地址逻辑距离最近的节点上。
这个推送的实现过程可以简化为一句话:
当节点收到数据时,在所连接的邻近节点中,寻找与这个数据的内容地址更近的节点,然后推送给这些节点。
数据的读取过程也可以简化为一句话:
当节点收到数据读取请求时,首先看自身有没有缓存内容地址所对应的数据,如果有,直接取出返回给请求者;如果没有在所连接的邻近节点中,寻找与内址地址更近的节点,把数据读取请求转发给这些节点。
上述的简单方案就可以实现数据的推送和读取。实际的实现中,需要考虑很多异常因素,我们此处不表。
Swarm与IPFS对比
Swarm其实不是存储系统,而是流量分发系统。为什么这么说呢?我们先看一下IPFS系统。
IPFS是存储系统,当文件存储到IPFS节点A上时,IPFS会把文件的信息推送到全网某个地方,后续有其他节点B需要数据时,从该节点获取该文件的文件信息。
这个文件信息中包含文件所在的节点,因此B就知道了文件在A这里,因此B试图与A连接,从A读取文件数据。当节点B读取了文件数据后,同样把自身有的这个文件(或是文件中某个片断)的信息推送到全网某个地方。
后续当节点C需要读取文件时,从全网中找到A和B都有这个文件数据,然后试图连接这两个节点(A和B)读取文件数据,显然随着文件被读取次数的增加,文件在网络中扩散的越多,读取速度也越快,但是在初期速度非常慢,甚至有可能读不到(假设A和B都在内网里),因此IPFS系统里有网络穿透的概念,此处不多描述。
在SWARM中,文件按照4KB大小的片段切割形成一个金字塔结构。然后按照算法将每个片段不断推向某个地方,在推送的过程中,所有的中间节点都会缓存一份数据。
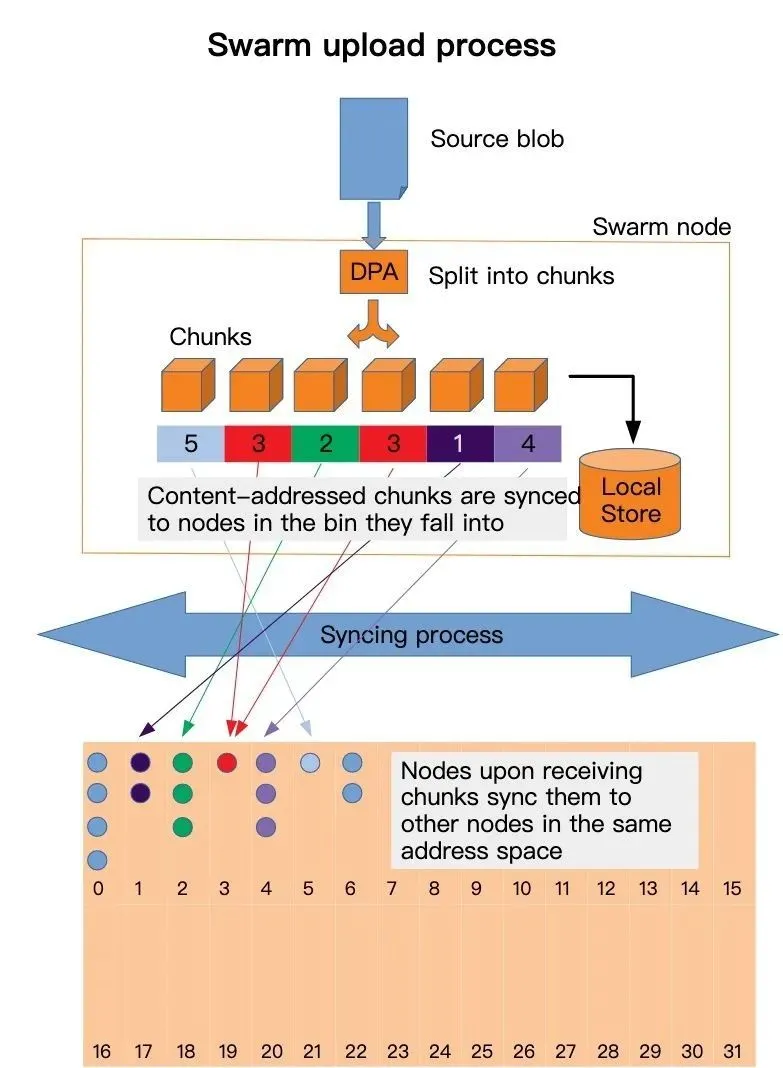
当需要读取该文件时,首先从某个地方读取到这个文件的根,然后从根中读取不同的文件片段信息,然后根据不同的片段从网络中不同的地方读取出相应的内容。
从上述可以明显看到,数据一旦被提交到swarm网络,会被自动切分并且分散推送到全网的不同节点,而在ipfs网络中,这个数据如果没有人读取是不会被扩散的。
swarm的方式可能会提高数据的读取性能,但是数据会被自动推送到不需要存储数据的节点上,浪费宝贵的存储和带宽,这个是IPFS里明确避免的。
反正有得必有失,有失必有得,通过自动扩散,数据内容自动传播到网络中的不同节点以备读取,所以我称其为内容分发系统。
IPFS和Swarm各有其缺陷和优点,那能不能综合两者呢?这个是我们正在做的事情,以后有机会再写文章。
SWARM挖矿分析
从上述原理就可以看出来,Swarm更注重的是流量,而流量传输有一个问题:
流量的传输内容和大小,只有传输的双方知道,链上其他节点不知道。
其实数据的存储也是一样,数据的存储正确与否,大小多少也是只有存储的需求者和提供者知道,要想让其他人知道怎么办?需要使用零知识证明,Filecoin就是实现了这个零知识证明,此处按下不表。
流量传输的这个问题导致另外一个问题:
由于流量传输的内容和大小,其他节点不知道,因此链上不能使用这个流量的大小作为算力。大家知道,区块链里面的算力是出块的依据,即节点算力占全网算力的比例就是节点出块的概率,这样才是公平的出块机制。流量不能作为算力就意味着不能通过流量进行出块奖励。
因此SWARM无法实现仅基于流量的区块链系统,即流量必须依赖于另外一条主链。
在swarm中,主链依赖以太坊,目前使用的以太坊的测试链,官方号称未来将基于以太坊主网,在这里我可很明确地和大家说,这是99.99999999%不可能的。(在这里坐等打脸)
那不通过流量给过出块奖励,挖矿挖个啥,难道挖了个寂寞?其实也不是,挖的是流量费,即数据的请求节点向服务节点支付流量费,所以节点的收益来源于其他节点给的流量费。
那这样也有问题,流量费是后支付还是先支付?
如果是后支付,请求节点会不会拿了数据后不支付流量费?
如果是先支付,服务节点会不会拿了流量费不给数据?
为了解决这个问题,可以采用逐步支付的机制,即服务节点每传输一段数据(比如说1M),等待请求节点回一个收据(或者叫支票),如果你不回支票给我,那我后面就不传数据给你,并且把你拉入黑名单,这样服务节点即使损失,也就损失一小部分流量费。
而请求节点作恶多了,全网就没有节点会答理他了,也是因小失大。通过这样的方式可以实现流量的计费。
但是上述方案有一个总是,一段数据设置成多大比较合适?如果设置的比较小,比如是1MB,如果100Mbps的网络节点,每秒都需要产生一个收据,全网假如几十万节点,这个收据(支票)的数据量巨大无比,根本不可能处理的过来。如果设置的比较大,那请求节点可能会逃费。
这个问题就需要可合并的收据(支票),swarm里没有做这个事,会不会有问题?目前测试网12万个节点已经很堵了(别忘了测试网的流量应该很小哦),未来主网上,应该问题会更重。
这些收据(支票)提交给链上,链上根据收据的签名和目标,将相应的代币从数据的请求者节点转移到服务者节点,这个是通过智能合约来实现的。
因此,我们可以得到以下几个结论:
Swarm挖矿没有出块奖励,是节点之间的流量费互传;
由于1,节点能够收到的流量费的上限与带宽有关,带宽越高,流量费上限越高;
另外,节点能够传输的流量还受限于节点的系统瓶颈,而在swarm方案中,系统瓶颈是磁盘IO。
根据上述2和3,可以推断矿机的硬件需求和配置
SWARM矿机
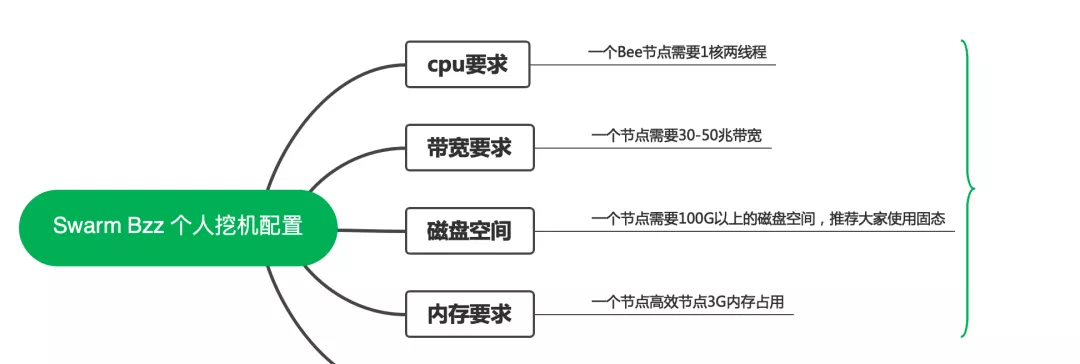
由于FIL的前车之鉴,导致很多人以为SWARM也会象FIL那样矿机要求在不停变,所以不敢推荐矿机方案,实现上SWARM和FIL是不一样的。我们可以分析出SWARM的瓶颈以及配置方案。
SWARM中每个片段大小为4KB,数据存储于磁盘上,因此数据的访问能力受限于磁盘IO,我们可以根据磁盘的IOPS(每秒读写IO次数)性能计算出每一种磁盘的SWARM读写性能:
HDD硬盘:HDD硬盘的IOPS最高约为在76(7200转)到166(15000转)之间,因此读写性能在 (76~166)x4KB=300KB-664KB每秒!!如果折算成带宽,就是一个3-6Mbps,也就是说,如果使用一个机械硬盘,即使在一台机器上运行了再多的节点,使用了再多的带宽,也只有最高3-6Mbps带宽的收益上限,惊不惊喜?意不意外?
SSD:SSD的IOPS最高大约在4万,因此读写性能的极限在40000x4KB = 160000KB = 160MB。折算成带宽,大约在1.6Gbps。同样一台机器上运行再多的节点,使用再多的带宽,收益的上限是1.6Gbps!
由于SWARM使用了4K片段,因此磁盘IO的读写性能就是标准的4K随机读写性能,可以在网上查询磁盘的4K随机读写性能
因此我们可以得到如下的结论:
使用机械硬盘作存储,还在上面跑多个节点是扯淡的,没知识没文化的无脑方案
每个SSD硬盘可以支持大约1Gbps的带宽(片段信息的管理也需要用掉一部分的磁盘IO).
通过前面的原理描述,文件片段被自动推送到不同的节点,而读取时,自动从不同的节点上读取数据,因此自然推理,是不是多个节点就能收到更多的文件片段数据,被读取的概率更大一些,从而获得更多的收益?
答案是肯定的,因此我们可以在一台物理节点上尽可能地跑多个节点,从而获得更多的收益,当然就别使用HDD的,使用HDD跑再多也没有用。这时候,我们需要考虑另外系统的瓶颈了:CPU。当节点跑得起多,CPU需求就越高,不同的CPU的性能不同,此处就无法给出定量的数据了。
因此,我们可以得到另外一个结论:
当使用SSD,网络带宽足够的情况下,运行更多的节点将会带来更多的收益。
实际上,当跑多个节点,比如说5个以上的时候,明明带宽没满,磁盘IO也满了,这个是由于代码本身没有做优化导致的。至于该怎么优化,后续文章再详细讨论。
关于SWARM的未来
在我看来,SWARM是一个非常伟大的项目,在很多地方做出了有益的尝试,但是目前的实现还未能够到达满足实际应用需求的程度。在可见的将来能够落地取得大规模商用是几乎不可能的,但是作为区块链项目,是非常值得参与的。
链芯云证BZZ物理节点全网首发
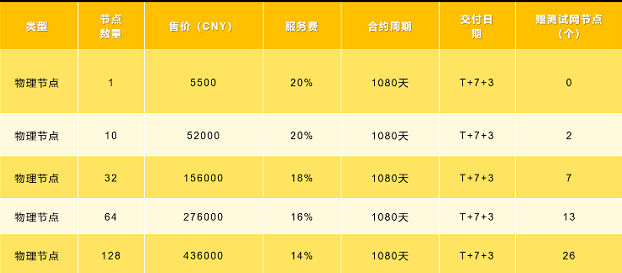
链芯云证Swarm物理节点火热发售——为庆祝Swarm主网即将上线,链芯云证现正式推出Bzz物理节点销售计划,现在参加预售即赠送测试网节点!全网最优性价比,200个测试节点,赠完为止!
销售细则
活动备注
本次活动为预售物理节点,不含宽带费用,后期宽带费用按主网上线后实际成本按月续费,测试网挖矿期间测试币和服务器由公司提供,主网上线后若需质押币和Gas币需用户自行提供。
链芯云证科技有限公司隶属广州一家科技集团公司旗下高科技企业,是一家以软件与信息技术研发与存储为主的公司。公司主营范围有:数据处理和存储服务、信息系统集成服务、网络安全信息咨询的高科技公司,链芯云科技主要为用户提供矿机共享租赁,算力买卖,矿机买卖、技术服务,公司成立至今,矿机规模超5万台。

